
Você se importa com o Desempenho de suas aplicações? Então é fundamental que você entenda o que é o Problema do N + 1 e saiba como identificá-lo e corrigi-lo.
Essa é uma grande falha que muitos programadores iniciantes (e até intermediários) não conhecem, deixando as aplicações muito lentas e tendo uma grande perda de performance.
Continue lendo este artigo, que vou explicar em detalhes o que é o Problema do N + 1 e como solucioná-lo.
O Que é o Problema do N + 1
Para explicar o que é esse problema, vamos considerar um banco de dados com duas tabelas: uma tabela de usuários e uma tabela de posts, como mostrado na imagem a seguir.
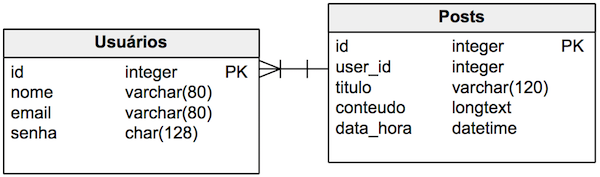
A tabela Usuários armazena os dados dos usuários, como nome, email, senha etc. A tabela de posts, além dos dados dos posts, como título e conteúdo, também possui o campo user_id, que referencia o ID do usuário que criou o post.
Até aí tudo bem. Modelagem bem simples.
Agora imagine que você precisa montar uma tela onde serão exibidos todos os usuários e os títulos de todos os posts de cada um deles.
O que muitos fariam é o seguinte:
- Selecionar todos os usuários, com a consulta a seguir:
SELECT id, nome FROM usuarios;
- Em seguida, para cada usuário, seria feita a consulta a seguir:
SELECT titulo FROM posts WHERE user_id = id_do_usuario;
Supondo que temos 100 usuários, serão executadas todas estas consultas:
SELECT id, nome FROM usuarios;; SELECT titulo FROM posts WHERE user_id = 1; SELECT titulo FROM posts WHERE user_id = 2; SELECT titulo FROM posts WHERE user_id = 3; ... SELECT titulo FROM posts WHERE user_id = 100; |
Veja que seriam feitas 101 consultas. E é aqui que você vai entender o motivo do N + 1.
Considerando N o número de usuários, nosso N vale 100. E N + 1 é 101, que foi o total de consultas realizadas.
Consultas a bancos de dados tomam tempo. Muito tempo. Por isso devemos usar sempre o mínimo de consultas.
E 101, definitivamente, não é o mínimo para chegarmos ao resultado esperado.
Esse número é BEM MENOR que 101… MUTO MENOR MESMO!
Você vai entender logo logo.
Como Identificar o Problema do N + 1
É simples identificar esse problema. Sempre que houver uma consulta dentro de um loop, é bem provável que ali esteja ocorrendo esse problema.
Vamos a um simples exemplo, usando PHP:
$PDO = new PDO( "dados de conexão aqui" ); $sql = "SELECT id, nome FROM usuarios"; $stmt = $PDO->prepare( $sql ); $result = $stmt->execute(); $users = $stmt->fetchAll( PDO::FETCH_ASSOC ); foreach ( $users as $user ) { $sql = "SELECT titulo FROM posts WHERE user_id = :user_id"; $stmt = $PDO->prepare( $sql ); $stmt->bindParam( ':user_id', $user['id'] ); $result = $stmt->execute(); $posts = $stmt->fetchAll( PDO::FETCH_ASSOC ); } |
NOTA: Caso você não conheça PDO, recomendo ler este artigo.
Veja que existe uma consulta dentro do loop. Ou seja, serão feitas N consultas, sendo N o total de elementos do array $users (100, no nosso caso).
Como Resolver o Problema do N + 1
Resolver esse problema é muito simples!
Vamos reduzir o números de consultas de N + 1 para APENAS 2!
Vamos usar SOMENTE DUAS CONSULTAS!
A primeira vai continuar sendo a mesma de antes, responsável por buscar todos os usuários:
SELECT id, nome FROM usuarios |
Porém, a segunda vai usar os dados dessa consulta e trazer todos os posts de todos os usuários. Depois basta iterar sobre o array, dentro da programação.
A consulta usará a função IN() na cláusula WHERE, desta forma:
SELECT titulo FROM posts WHERE user_id IN(1,2,3,4,5,...,100); |
Vou modificar o código anterior e mostrar como resolver o Problema do N + 1 para o caso que analisamos.
$PDO = new PDO( "sua conexão aqui" ); $sql = "SELECT id, nome FROM usuarios"; $stmt = $PDO->prepare( $sql ); $result = $stmt->execute(); $users = $stmt->fetchAll( PDO::FETCH_ASSOC ); $userIDs = array_column( $users, 'id' ); $sqlIDs = implode( ',', $userIDs ); $sql = sprintf( "SELECT titulo FROM posts WHERE user_id IN(%s)", $sqlIDs ); $stmt = $PDO->prepare( $sql ); $result = $stmt->execute(); $posts = $stmt->fetchAll( PDO::FETCH_ASSOC ); |
Voilà!
Note que, até a criação da variável $users, nada mudou. Depois disso é que apareceram as novidades. Vamos analisá-las com mais calma.
Criei a variável $userIDs, que é um array com todos os valores do campo id que estavam no array $users. Isso ficou fácil usando a função array_column.
Em seguida criei a variável $sqlIDs, usando a função implode. Essa variável é uma string com todos os IDs separados por vírgula, de forma que possa ser usada no parâmetro da função IN da SQL.
Depois criei a variável $sql, que vai buscar todos os posts com uma única consulta.
Analisando o Ganho de Desempenho
Vamos fazer um simples teste de desempenho, para comparar os dois códigos que vimos anteriormente.
A análise é simples: pegar a hora de início do script, a hora final e subtrair. Para isso, usarei a função microtime, para pegar o tempo atual em micro-segundos, e a função number_format, para formatar o tempo de maneira a ficar mais facilmente legível.
A ideia geral, em termos de código é a seguinte:
$inicio = microtime( true ); // código cujo desempenho queremos testar $fim = microtime( true ); $diff = number_format( $fim - $inicio, 15, ',', '.' ); echo "Tempo total: " . $diff . PHP_EOL; |
Para testar, criei 100 registros na tabela de usuários, com valores aleatórios. Criei 1000 registros, também aleatórios, na tabela de posts.
Vamos aos resultados…
O script contendo o Problema do N + 1 foi executado em 0,0198240280 segundos.
Já o script sem o problema foi executado em 0,0015311241 segundos. Ou seja, aproximadamente 13 vezes mais rápido.
13 VEZES MAIS RÁPIDO!
E olha que o exemplo tinha poucos dados. Um sistema real geralmente tem muito mais que 100 usuários e mais de 1000 registros relacionados a eles.
Por que não usei JOIN em vez do IN
É possível resolver esse problema com apenas uma consulta, usando JOIN em vez de IN, desta forma:
SELECT u.id, u.nome, p.titulo FROM usuarios u INNER JOIN posts p ON p.user_id = u.id |
Mas isso não significa que será mais eficiente.
O foco aqui é Desempenho, não apenas menos consultas.
Se cada usuário tivesse apenas um post, poderia ser mais eficiente usar JOIN. Mas se, por exemplo, cada usuário tiver, em média, 100 posts, haverá milhares de dados repetidos trafegando entre o banco de dados e sua aplicação. E isso tomará tempo e memória.
Já que estamos fazendo testes práticos, vamos comparar os tempos de execução de dois scripts, um usando o IN (que é o mesmo código que mostrei anteriormente) e outro usando JOIN.
O código usando JOIN é este:
$PDO = new PDO( "conexão aqui" ); $sql = "SELECT u.id, u.nome, p.titulo FROM usuarios u INNER JOIN posts p ON p.user_id = u.id"; $stmt = $PDO->prepare( $sql ); $result = $stmt->execute(); $posts = $stmt->fetchAll( PDO::FETCH_ASSOC ); |
Vou mostrar os resultados para um conjunto de 100 usuários e 1000 posts. Em seguida, vou inserir mais 4000 posts, resultando em 100 usuários e 5000 posts.
Alguns resultados de execução para 100 usuários e 1000 posts:
$ php select_join.php && php select_in.php Tempo total com JOIN: 0,002864837646484 Tempo total com IN: 0,002188920974731 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,002944946289063 Tempo total com IN: 0,001436948776245 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,003201961517334 Tempo total com IN: 0,001392841339111 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,002935886383057 Tempo total com IN: 0,001415014266968 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,002933025360107 Tempo total com IN: 0,001442193984985 |
Agora vamos a alguns resultados usando 100 usuários e 5000 posts:
$ php select_join.php && php select_in.php Tempo total com JOIN: 0,011201143264771 Tempo total com IN: 0,002874851226807 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,010854005813599 Tempo total com IN: 0,002540111541748 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,010561943054199 Tempo total com IN: 0,002592086791992 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,010941982269287 Tempo total com IN: 0,002531051635742 $ php select_join.php && php select_in.php Tempo total com JOIN: 0,010515928268433 Tempo total com IN: 0,002762794494629 |
Fiz cinco execuções de cada script para cada conjunto de dados.
De todos os 10 testes, 9 resultaram em desempenho superior na versão usando IN. O uso do JOIN ficou superior apenas na primeira execução com 1000 posts.
Não estou falando para abandonar o JOIN e usar só o IN. Tudo depende da sua modelagem e da quantidade de dados. Para poucos dados ou relação 1 Para 1, o JOIN será melhor. Mas em relação 1 Para Muitos, o IN tende a ter melhor desempenho.
Conclusão
Melhorias de desempenho são sempre muito bem-vindas. Qualquer ajuste que dê 5% de ganho já é válido.
E considerando que aqui tivemos 13 vezes mais (ou seja, 1300%), você definitivamente precisa saber identificar e resolver o Problema do N + 1 nas aplicações que você desenvolve ou dá manutenção.
É uma medida simples e que dá resultados fantásticos!
Otimizações Avançadas
Há inúmeras outras formas mais avançadas de otimizar seu banco de dados.
Para conhecer essas técnicas, recomendo o curso Tuning MySQL (curso em português), especialmente voltado para o MySQL, um dos mais usados do Mercado.
Você vai aprender passo-a-passo como instalar e configurar o MySQL da forma mais otimizada para a sua aplicação, conhecendo cada um dos arquivos de configuração e suas diretivas. Também vai descobrir como realizar análises de desempenho e testes de stress, para comparar o desempenho padrão e o desempenho obtido após o tuning.
Clique Aqui e conheço o Curso Tuning MySQL



 Sou Roberto Beraldo (ou apenas Beraldo), desenvolvedor PHP há mais de 15 anos, numa jornada de desenvolvimento para me aprofundar no mundo DevOps e Cloud. Bacharel em Ciência da Computação, com uma base sólida em desenvolvimento web e conhecimentos em DevOps e Computação em Nuvem. Estou dedicado a conectar o desenvolvimento de software com a gestão de infraestrutura.
Sou Roberto Beraldo (ou apenas Beraldo), desenvolvedor PHP há mais de 15 anos, numa jornada de desenvolvimento para me aprofundar no mundo DevOps e Cloud. Bacharel em Ciência da Computação, com uma base sólida em desenvolvimento web e conhecimentos em DevOps e Computação em Nuvem. Estou dedicado a conectar o desenvolvimento de software com a gestão de infraestrutura.